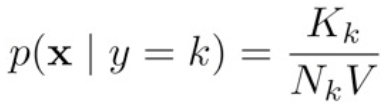Diferencias entre Regresión y Clasificación:
• En la regresión, Y, la variable dada a las clases, es continua, en la clasificación es discreta
• La regresión aprende una función, la clasificación normalmente aprende etiquetas de clase.
Por ahora vamos a tratar de regresión.
Funciones de Base:
En principio, los elementos de X pueden ser cualquier cosa (por ejemplo, números reales, gráficos, objetos 3D). Para poder tratar estos objetos matemáticamente necesitamos funciones que asignen un número real a partir de X. Llamamos a estas las funciones de base.
También podemos interpretar las funciones de base como las funciones que extraen las características de los datos de entrada. Estas características reflejan las propiedades de los objetos (anchura, altura, etc.)
El problema de regresión lineal puede ser planteado como sigue:
Asumir que X pertenece a los números Reales, Y pertenece a los números Reales también, la función Ø es la identidad (I)
Dados: Puntos de datos (x1,t1); (x2,t2), ...
Objetivo: Predecir el valor de t para una nueva muestra de x.
Formulación Paramétrica: y(x,w)=w0+w1x

Para llegar al objetivo podemos usar el error cometido (líneas verdes) entre el valor predicho al evaluar la función (línea negra) y el valor de un punto dado(puntos rojos).
Si usamos la suma de todos esos errores sin importar el signo (puesto que hay puntos arriba y abajo de la línea) basta con conocer cuales w0 y w1 minimizan dicho error, logrando que el valor predicho tenga poco error
A la siguiente función de error se le llama suma de error cuadrático medio:

Como el error es elevado al cuadrado y se busca minimizarlo a este método se le conoce como mínimos cuadrados. La manera en que se halla el mínimo de una función es derivándola, como w =[w0 w1] es decir no es una variable única si no varias se utiliza el operador de gradiente (triángulo invertido) que deriva la función para cada variable quedando de resultado otro vector.

Con estas dos ecuaciones es posible llegar al resultado, veamos con un programa en Scilab, usando la formula resultante:

Primero daremos puntos cercanos a una recta conocida, luego calcularemos w aplicando la función linsolve(A,b) que resuelve el problema de álgebra lineal Ax+b=0. Pondremos todo dentro de una función reglineal(x,t), que recibe como datos los puntos y devuelve w y la gráfica de los puntos y la recta encontrada.
En un archivo nuevo en SciNotes copia y guarda como reglineal.sci
//Función que realiza la regresión lineal de los puntos dados
//x: es un arreglo(vector) unidimensional correspondiente a la variable x. Arreglo(float)
//t: es un arreglo(vector) unidimensional correspondiente a la variable t. Arreglo(float)
//w: Son los coeficiente de la funci[on lineal. Arreglo(float)
function w = reglineal(x, t )
xi=[ones(1,length(x));x];
A=(xi*xi')'//la comilla simple significa transponer o el superindice T de las ecuaciones
b=(t*xi')';
w=linsolve(A,-b);//Es -b pues tiene que volver del otro lado del igual
y=w'*xi;
figure();
plot(x,t,'or'); //La 'o' hace que se dibujen solo los puntos, la 'r' que sean rojos.
plot(x,y,'k'); //la 'k' hace negra la linea.
endfunction
En otro archivo o copiando directamente en la interfaz de comandos pon:
clc
x=[0 1 2 3 4 5 6 7 8 9];
t=[3 8 13 18 23 28 33 38 43 48];
w=reglineal(x,t);
disp(w, "Los coeficientes w resultaron");
//El resultado debe ser [3 5], es decir y=3+5*x.
////Ahora observemos que pasa al ingresar las varibles en otro orden
//Se espera la misma expresion despejando x=-3/5+1/5*y= -0.6+0.2y
w1=reglineal(t,x);
disp(w1, "Los coeficientes al invertir las variables son ");
//por ultimo ingresemos valores no exactos para ver a que se aproxima
xh=[0 1 2 3 4 5 6 7 8 9];
th=[4 6.5 11.7 16 25 28.5 32 37.8 44 48.1];
w2=reglineal(xh,th);
disp(w2, "Los coeficientes ahora son son ");
w3=reglineal(th,xh);
disp(w3, "Los coeficientes al invertir las nuevas varibles son ");
//Ahora observemos como no necesariamente se llega al mismo resultado al ingresar las variables en otro orden
//Se espera x=-0.473140+0.1961017y
El problema de regresión polinómica se plantea como sigue:
Asumir que X pertenece a los números Reales, Y pertenece a los números Reales también, la función Øj es x elevado a la j.
Dados: Puntos de datos (x1,t1); (x2,t2), ..., (xN,tN)
Objetivo: Predecir el valor de t para una nueva muestra de x.
La función paramétrica se muestra en la figura, donde M es la complejidad dado que indica el número de coeficientes de y.
Al poner y(x,w) con notación vectorial, considerando Ø(x) también como un vector:

Al igual que en el caso anterior se debe minimizar E(w), pero ahora no son solo dos variables sino N variables.
Al final queda:

Con:

Realizemos el siguiente ejercicio en Scilab:
Copia la siguiente función y guarda como regpolinomial.sci
//Función que realiza la regresión polinomial de los puntos dados
//x: es un arreglo(vector) unidimensional correspondiente a la variable x. Arreglo(float)
//t: es un arreglo(vector) unidimensional correspondiente a la variable t. Arreglo(float)
//m: es la complejidad del polinomio, m-1 es el grado
//w: Son los coeficientes del polinomio. Arreglo(float)
function w = regpolinomial(x, t ,m)
for i=1:length(x)
for j=1:m
phi(i,j)= x(i)^(j-1);
end
end
A=phi'*phi
b=phi'*t';
w=linsolve(A,-b);//Es -b pues tiene que volver del otro lado del igual
y=w'*phi';
figure();
plot(x,t,'or'); //La 'o' hace que se dibujen solo los puntos, la 'r' que sean rojos.
plot(x,y,'k'); //la 'k' hace negra la linea.
endfunction
Copia el siguiente código en un archivo o directamente en la interfaz de comandos:
clc
//Datos aleatorios
x=[0 1 2 3 4 5 6 7 8 9];
t=[2 13 20 53 78 83 98 103 128 125];
m=4;
w=regpolinomial(x,t,m);
disp(w, "Los coeficientes w con m=3 resultaron ");
w1=regpolinomial(t,x,m);
disp(w1, "Los coeficientes w al invertir el orden de entrada de los puntos esultaron");
m=32;
w2=regpolinomial(x,t,m);
disp(w2, "Los coeficientes w con m=32 resultaron");
w3=regpolinomial(t,x,m);
disp(w3, "Los coeficientes w con m=32 al invertir el orden de entrada de los puntos resultaron");
En las diapositivas también encontramos este ejemplo:


En las primeras 4 gráficas se observa los resultados al aumentar la complejidad, al igual que en nuestro ejercicio en Scilab, es evidente que aumentar la complejidad no necesariamente ayuda a obtener un mejor ajuste, puede empeorar o producir sobreajuste (N=10, M=10), por el contrario en las 4 gráficas siguientes se observa como el añadir puntos de datos si mejora el ajuste obtenido.
Se puede usar otras funciones base, como la gaussiana


Y la sigmoidal:

Como se aprecia en todas las figuras la complejidad de la regresión debe llegar a ser la adecuada par obtener un buen resultado y debido a que el número de datos disponibles generalmente es fijo se debe hallar cual debe ser ese nivel de complejidad .