Esta red neuronal se compone de dos entradas, una capa oculta con 2 neuronas y una salida en la ultima capa. El esquema de la red neuronal se muestra en la siguiente figura:

El programa calcula los pesos del esquema utiiliando el metodo de Back Propagation con el metodo de aprendizaje delta.
PERCEPTRON CON UNA CAPA OCULTA Back Propagation XOR
%BOTON ENTRENAR.
function btEntrenar_Callback(hObject, eventdata, handles)
%Obtener Datos de Tabla
datos=get(handles.Tabla,'Data');
x1=datos(:,1);
x2=datos(:,2);
yd=datos(:,3);
%Otener datos iniciales de pesos y bias
w110= str2double(get(handles.w110,'String'));
w120= str2double(get(handles.w120,'String'));
w210= str2double(get(handles.w210,'String'));
w220= str2double(get(handles.w220,'String'));
v10= str2double(get(handles.v10,'String'));
v20= str2double(get(handles.v20,'String'));
u210= str2double(get(handles.u210,'String'));
u220= str2double(get(handles.u220,'String'));
u30= str2double(get(handles.u30,'String'));
alfa= str2double(get(handles.alfa,'String'));
%Otener datos de iteraciones y error
iteracionmax = str2double(get(handles.Iteraciones,'String'));
errormax = str2double(get(handles.Error,'String'));
%ENTRENAMIENTO
w11= w110;
w12=w120;
w21= w210;
w22= w220;
v1= v10;
v2= v20;
u21= u210;
u22= u220;
u3= u30;
condicion = 0;
iteracion = 0;
error_Total = zeros(1,iteracionmax+1);
while(condicion == 0)
for j = 1 : 4
%Calcular la yObtenida
%Capa Entrada
z1 = x1(j);
a11 = z1;
z2 = x2(j);
a12 = z2;
%Capa Oculta
z3 = a11*w11+a12*w21 + u21;
a21 = funcion_activ(z3);
z4 = a11*w12+a12*w22 + u22;
a22 = funcion_activ(z4);
%Capa Salida
z5 = a21*v1 + a22*v2 + u3;
yObtenida = funcion_activ(z5);
%Calculamos error yObtenida*(1-yObtenida)*
err = (yd(j)- yObtenida);
%Correccion pesos Capa 2-3
z= v1*a21+v2*a22+u3;
d3 = err*derivada_fun_act(z);
v1 = v1 + alfa*d3*a21;
v2 = v2 + alfa*d3*a22;
u3 = u3 + alfa*d3;
%Correccion pesos Capa 1-2
d21 = derivada_fun_act(z3)*v1*d3;
w11 = w11 + alfa*d21*a11;
w21 = w21 + alfa*d21*a12;
u21 = u21 + alfa*d21;
d22 = derivada_fun_act(z4)*v2*d3;
w12 = w12 + alfa*d22*a11;
w22 = w22 + alfa*d22*a12;
u22 = u22 + alfa*d22;
%Contar error total
error_Total(iteracion+1) = error_Total(iteracion+1)+abs(err);
end
iteracion = iteracion +1
if(iteracion >= iteracionmax)
condicion =1;
end
if (error_Total(iteracion) <= errormax)
condicion =1;
end
end
%Mostrar los Resultados
set(handles.w11,'String',num2str(w11));
set(handles.w12,'String',num2str(w12));
set(handles.w21,'String',num2str(w21));
set(handles.w22,'String',num2str(w22));
set(handles.v1,'String',num2str(v1));
set(handles.v2,'String',num2str(v2));
set(handles.u21,'String',num2str(u21));
set(handles.u22,'String',num2str(u22));
set(handles.u3,'String',num2str(u3));
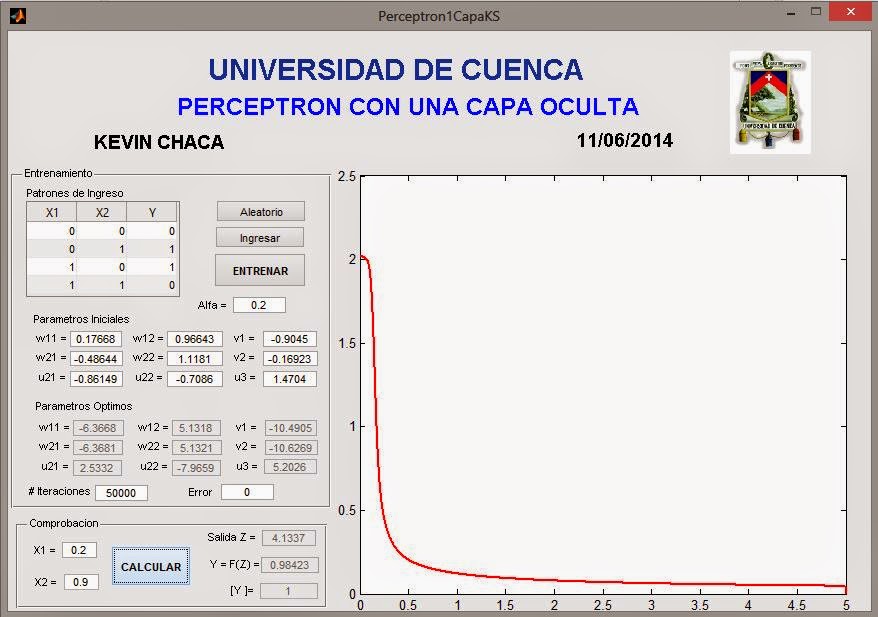
%Dibujar el error
axes(handles.axes1);
x=0:1:iteracionmax;
plot(x,error_Total,'color','r', 'LineWidth', 2);
end
function f = funcion_activ(z)
%SIGNOIDE
f = 1/(1+exp(-z));
end
function fp = derivada_fun_act(z)
%SIGNOIDE
fp = (1-funcion_activ(z))*funcion_activ(z);
end



















